You are viewing the RapidMiner Radoop documentation for version 9.4 - Check here for latest version
Accessing Hive from Spark Script
Spark Script allows you to extend your processes with custom scripts. In those scripts you can access Hive tables / views directly and use HiveQL syntax if the cluster-side settings allow this. The purpose of this section is to go through the requirements to enable this feature.
Access to Hive in a Spark code is provided by HiveContext in Spark 1.x (starting from Spark 1.5) and by SparkSession in Spark 2.x. Both PySpark (Python) and SparkR (R) APIs have these features. Spark Script Radoop operator has a parameter called enable Hive access that needs to be explicitly checked to enable these APIs in the script.
However, sharing data between the Hive warehouse and Spark requires appropriate security settings on the cluster. The component responsible for authorizing access may be different between these two components. This section is an overview on solving this issue. Technically speaking, you need to setup the access to the Hive warehouse on HDFS and to the Hive Metastore for the user running the Spark Script on the cluster.
The user running the Spark Script job on the cluster can be determined the following way:
- When security (Kerberos authentication) is disabled, it is the Hadoop Username in the Radoop connection.
- When security is enabled, but user impersonation is disabled, the Client Principal is translated to a user by the auth_to_local rules on the cluster (
hadoop.security.auth_to_local). When both security and user impersonation (Enable impersonation on server) is enabled:
- in Server it is the RapidMiner Server user;
- in Studio the Client Principal is translated to a user by the auth_to_local rules on the cluster (
hadoop.security.auth_to_local), except when Impersonated user for local testing is set (for testing purposes), in which case the user is the user specified in that field.
For simplicity, let's call this user rmuser and its group rmgroup throughout this section.
The two main requirements are:
rmuser (or rmgroup) must have access to the Hive Metastore;
rmuser (or rmgroup) must have access to the particular HDFS files / directories in the Hive warehouse directory (those files that belong to the Hive tables used in the script).
On a cluster with only Storage Based Authorization in Hive, the second requirement still means that rmuser must have read / write permissions (depending on the operation) to the HDFS files and folders that contain the Hive table content. To generally make all types of operations possible in a Spark Script, the user must have all permissions (rwx) on the Hive warehouse directory on HDFS.
On a cluster with more advanced authorization components, the settings for these requirements depend on the authorization setup. The components responsible for authorization depend on the specific Hadoop distribution. You need to configure the component responsible for authorization (HDFS, Sentry, Ranger...) in way that allows this access.
Settings when using Apache Sentry for authorization
When Apache Sentry is used for authorization, then hive user (the user running HiveServer2) and group owns the Hive warehouse directory, and usually no other users have access to the files inside. This means that the user that rmuser (that runs the Spark job) does not have access to the contents of a table on HDFS. In order to properly allow access to these files for a user other than hive, the following steps are required in case of Sentry authorization:
Turn on the synchronization of Sentry Permissions and HDFS ACLs, and give required permissions to rmuser or rmgroup either in Sentry or using HDFS ACLs. You may decide to not turn on synchronization, but such a setup is not recommended by the Cloudera documentation.
The group rmgroup also needs access to the Hive Metastore. If that access is restricted, grant that access with the following steps (similar to the Block the Hive CLI user from accessing the Hive metastore steps in Cloudera documentation):
In the Cloudera Manager Admin Console, select the Hive service.
On the Hive service page, click the Configuration tab.
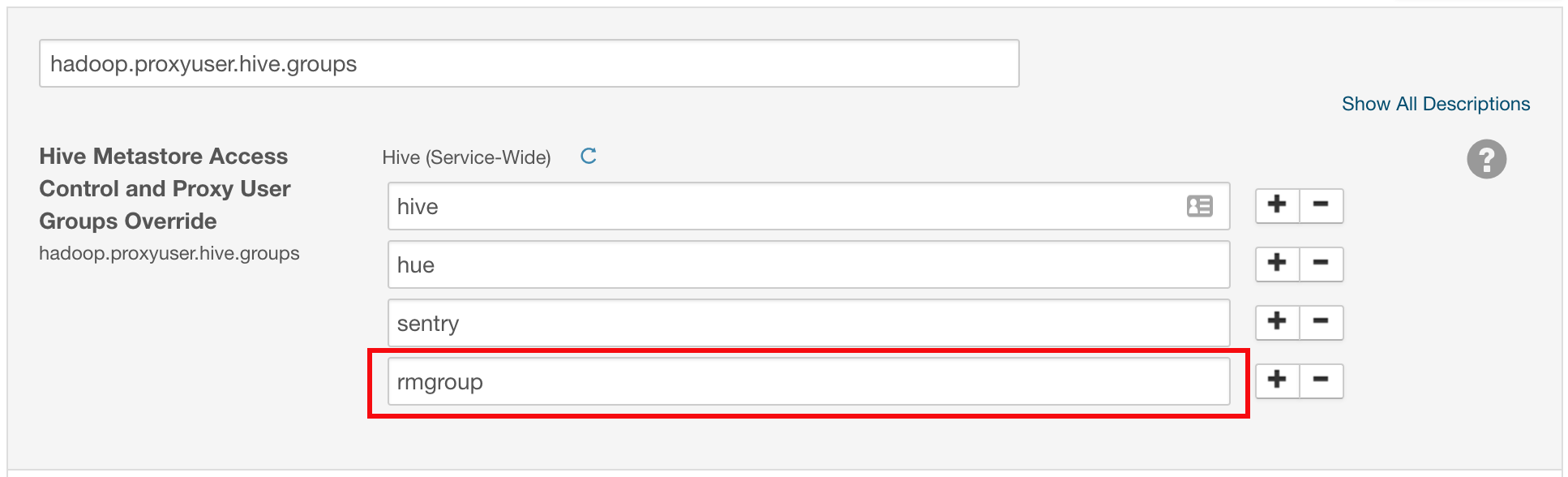
In the search field, search for Hive Metastore Access Control and Proxy User Groups Override to locate the
hadoop.proxyuser.hive.groupssetting.Click the plus sign to add the following group (replace
rmgroupwith the group that RapidMiner users belong to):rmgroupClick Save Changes.
Specifying a custom Spark Version
Radoop does not rely on any Spark service on the cluster. It only requires a Spark Assembly (Spark 1.x) or a Spark Archive (Spark 2.x) on HDFS or on the local file system (on all nodes). But when using Hive access in Spark 1.x (Spark 1.5+) via HiveContext, Hive jar files must be added to the classpath of the job - this is done automatically by Radoop. To avoid problems from this, it is not recommended to use a custom Spark Assembly that differs from what the Hadoop distribution ships when using Hive access in Spark 1.x scripts, because compatibility issues may arise. There is an explicit design-time warning in Spark Script operator in Studio if different Spark versions exist on the classpath.