You are viewing the RapidMiner Server documentation for version 9.0 - Check here for latest version
General Setup
This section describes the general setup of RapidMiner Server in a high availability environment and lists details and information as well as potential problems for the components of such a setup. The image below depicts how such a setup could look like:
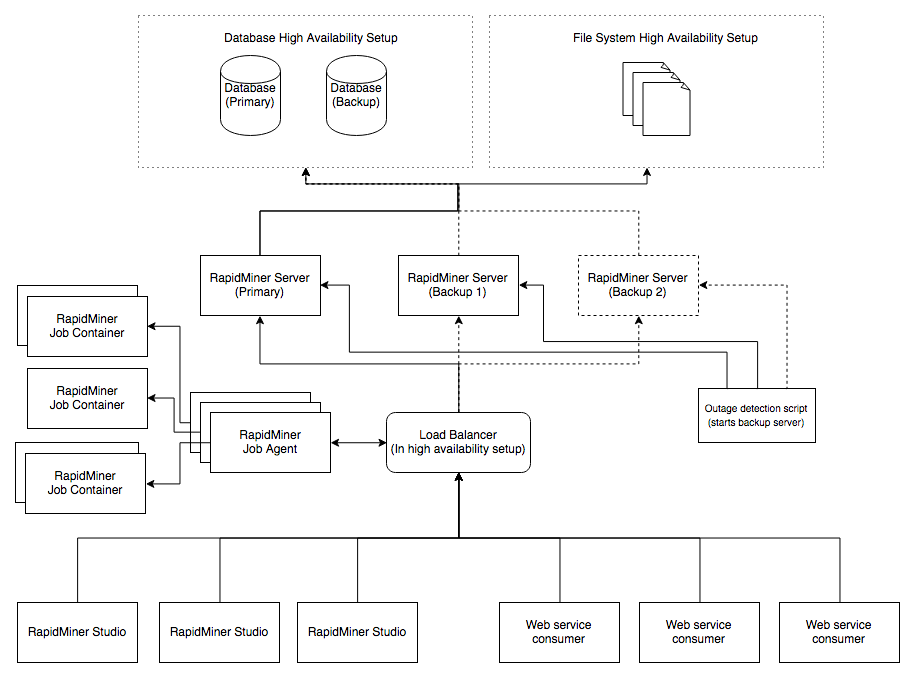
RapidMiner Server
As with regular setups, there will be one RapidMiner Server instance running and acting as the primary instance. This instance will serve all requests from Studio, as well as offer the web UI and potentially web services. Setting this instance up does not differ much from regular installations of RapidMiner Server, except for potential modification of the database access URL in case a high availability version of the database is used. Another possible change would be the host binding options of the server. The main difference will most of the time be that clients will not connect to this instance directly, but rather connect to a failover mechanism (e.g. a load balancer) which will then forward all requests to a healthy instance. This eliminates RapidMiner Server as a single point of failure, as a backup server can be started to take over if the primary server becomes unhealthy. As can be seen in the image above, there can be as many backup instances as desired. The only important part is, that only one instance is running at the same time. When the cold swap is happening, be aware that web UI sessions are dropped. All changes which had not yet been saved will therefore be lost. Furthermore, running and waiting processes will not be executed either. Connections from Studio and with web services though are stateless and as such can continue after the swap is complete with only a short interruption during the cold swap itself. See limitations for more details about what exactly is lost during a cold swap.
Note: If multiple instances of RapidMiner Server run at the same time on the same database, unpredictable behavior will occur!
Note: The primary server and the backup servers should not be located on the same machine. Otherwise a hardware or other failure of that machine will become the single point of failure.
Note: The data/ directory of the RapidMiner Server home directory needs to be mounted on a high-available network drive which is shared by every RapidMiner Server instance.
RapidMiner Job Agent
The RapidMiner Job Agent is designed to run on as many instances as desired. To utilize a high availability the RapidMiner Job Agents connect to the RapidMiner Server via the load balancer. One or more Job Agents can work on the same execution queue. Multiple Job Agents for the same queue can be used to minimize failure and to maximize concurrent execution performance. For further high availability of Job Agents an automatic monitoring is needed to resume the Job Agents's unwanted termination.
Note: The Job Agent instances should not be located on the same machine. Otherwise a hardware or other failure of that machine will become the single point of failure. For high availability it is recommended to place the Job Agent and the RapidMiner Server on different machines.
Database
The next potential single point of failure is the database which is backing the primary RapidMiner Server and the backup instance(s). It is highly recommended to use a high availability setup for your database! Otherwise if the database goes down, no RapidMiner Server instance will be able to work.
To utilize a high availability database for RapidMiner Server, usually all that needs to be done is adapt the JDBC connection URL in the standalone.xml located in the <home dir>/configuration/ folder of your RapidMiner Server home directory.
Please refer to the documentation of your database system for database high availability setup and further usage instructions.
Note: All RapidMiner Server instances (both primary as well as backups) must point to the same database(s), otherwise data inconsistencies and unpredictable behavior will occur!
Note: Modifying the JDBC connection URL is not enough, you will need to specifically set up your database system in high availability mode as well!
MySQL
MySQL does support multiple failover instances by adding all the instance locations to the JDBC connection URL. Apart from adding multiple instances, there are a few settings to tweak, which can be added as connection parameters directly behind the connection URL.
To do so, search for the <connection-url> element in the aforementioned standalone.xml file and change the JDBC URL to something like the following:
jdbc:mysql://masterHost:port,slaveHost1:port,slaveHost2:port/rms_schema?failOverReadOnly=false&optionalProperty1=optionalValue1
Note: By default the backup instances will be read-only, so make sure the failOverReadOnly is set to false!
For more information on MySQL failover functionality, see the MySQL documentation referenced below. MySQL failover documentation
MSSQL
MSSQL does support a failover instance by adding a failover partner to the JDBC connection URL. Apart from adding the failover partner name, you may need to specify a few settings as connection parameters directly behind the connection URL.
To do so, search for the <connection-url> element in the aforementioned standalone.xml file and change the JDBC URL to something like the following:
jdbc:sqlserver://masterHost:port;databaseName=rms_schema;failoverPartner=backupserver;optionalProperty1=optionalValue1;optionalProperty2=optionalValue2
Note: The failoverPartner is retrieved from the primary MSSQL database itself! Thus the failover partner name must be configured in the high availability setup of the primary database!
For more information on MSSQL failover functionality, see the MSSQL documentation referenced below.
- FailoverPartner documentation
- Connection properties documentation
- Advanced failover setup documentation
PostgreSQL
PostgreSQL does support multiple failover instances by adding all the instance locations to the JDBC connection URL. Apart from adding multiple instances, you may need to specify a few settings as connection parameters directly behind the connection URL.
To do so, search for the <connection-url> element in the aforementioned standalone.xml file and change the JDBC URL to something like the following:
jdbc:postgresql://masterHost:port,slaveHost1:port,slaveHost2:port/rms_schema?optionalProperty1=optionalValue1
For more information on MySQL failover functionality, see the MySQL documentation referenced below. PostgreSQL failover documentation
Oracle
Oracle does support multiple failover instances by adding the instance locations to the JDBC connection URL.
To do so, search for the <connection-url> element in the aforementioned standalone.xml file and change the JDBC URL to something like the following:
jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS_LIST=(LOAD_BALANCE=OFF)(FAILOVER=ON)(ADDRESS=(PROTOCOL=TCP)(HOST=masterHost)(PORT=port))(ADDRESS=(PROTOCOL=TCP)(HOST=slaveHost1)(PORT=port)))(SERVER=DEDICATED)))
Please refer to the Oracle documentation and support for detailed high availability setup and usage instructions.
Outage Detection
This is usually part of the load balancer setup to determine whether an instance is healthy or not.
RapidMiner Server comes with a REST service which can be queried for the health status of the server. This checks that RapidMiner Server has initialized correctly and it can successfully talk to its database.
To use the REST service, call http://server:port/api/rest/public/healthcheck and you will receive a JSON response telling you whether the server is healthy or not. In case it is healthy, the status code will be 200, if it is unhealthy, it will return 503. This check can be accessed without any authentication. It also uses a short-lived internal cache to avoid high load generation by calling this extremely frequently.
Note: Make sure that if you use an automated script it is not a single point of failure. It needs to run on multiple machines or otherwise be set up in a way that the actual outage detection does not become the single point of failure.
If the server is not healthy, the publicly available REST service will not provide details on what is wrong, but the server log will list the problems that caused the unhealthy state.
Failover Technologies
Some sort of failover technology (e.g. load balancing) is required for a working high availability setup. The most common setup is that every machine which wants to access RapidMiner Server goes to the IP address or domain name of the load balancer. These requests are then forwarded by the load balancer to the primary RapidMiner Server instance. If the load balancer detects that this instance is down, i.e. unhealthy, it will start forwarding all requests to a backup server which is detected as healthy. There are a multitude of possible ways to achieve this, some of which are listed below. Most of them have not been explicitly tested with RapidMiner Server but are expected to work due to the similar nature of them.
Note: The failover technology should also be set up in a way that it will not become the single point of failure of the entire RapidMiner Server high availability setup.
DNS-based
DNS-based failover technologies work by changing the domain name resolution of a given domain name depending on a health check condition. If the primary Server is detected to be unhealthy, the domain name used to talk to RapidMiner Server will be resolved to a different IP, i.e. that of a healthy RapidMiner Server instance. Examples:
- Hosts file-based: The
hostsfile of a system can override DNS resolution. Thus you can map a domain name to any given IP. If the primary server goes down, the file could be modified and direct to a different IP. Easy to set up but requires editing of a file on each client, thus not very feasible. - Monitor-based DNS server: The DNS server queries the health check of RapidMiner Server and can change its returned IP for the domain name used by clients to connect to RapidMiner Server. This usually requires all clients to talk to the specified DNS server for domain name resolution, unless the new IP is published to a public DNS.
IP-based
IP-based failover technologies work by assigning a single IP to the currently active server machine. The IP is unassigned from the primary server if it goes down and reassigned to a backup server. Example:
- Keepalived: A Linux-based solution for IP-based failover. Using the VRRP consensus protocol, the host with the highest priority becomes the master and gets the IP assigned. In case of failure of the master, the slave hosts can start a master election protocol and get the IP reassigned to one of the backup servers. Requires all servers to be in the same subnet.
HTTP-based
HTTP-based failover technologies describe regular load balancers. They work by forwarding all requests to predefined servers. These servers are taken in and out of the load balancer depending on regular health check results. See Outage Detection for a RapidMiner Server health check. In this case, you will only ever have one active server to forward requests to. Examples:
- nginx: Highly advanced load balancer with a plethora of customization options. Downsides are that high availability is not offered out of the box and the customization power results in a more complex setup.
- HAProxy: A robust load balancer with very simple configuration. A possible downside may be that it is only available for Linux.
- Amazon ELB: Part of the Amazon AWS EC2 offering. Very simple setup and can be configured for high availability. The downside is that it is only usable in combination with EC2 and that it is essentially a black box.
Other Components
To reiterate an important point, any component that is necessary for your high availability setup can be a potential single point of failure. This may be a single router, a certain network cable, etc. A fault on any of these might bring down your entire high availability setup. Therefore please ensure that all components of a high availability setup have backup(s) in place which can take over if a particular component fails.